
(WIP) Optimizing NVFP4 Grouped GEMM on Blackwell
238μs to 20μs using tcgen05 MMA, TMA async loads, cluster multicast, etc.
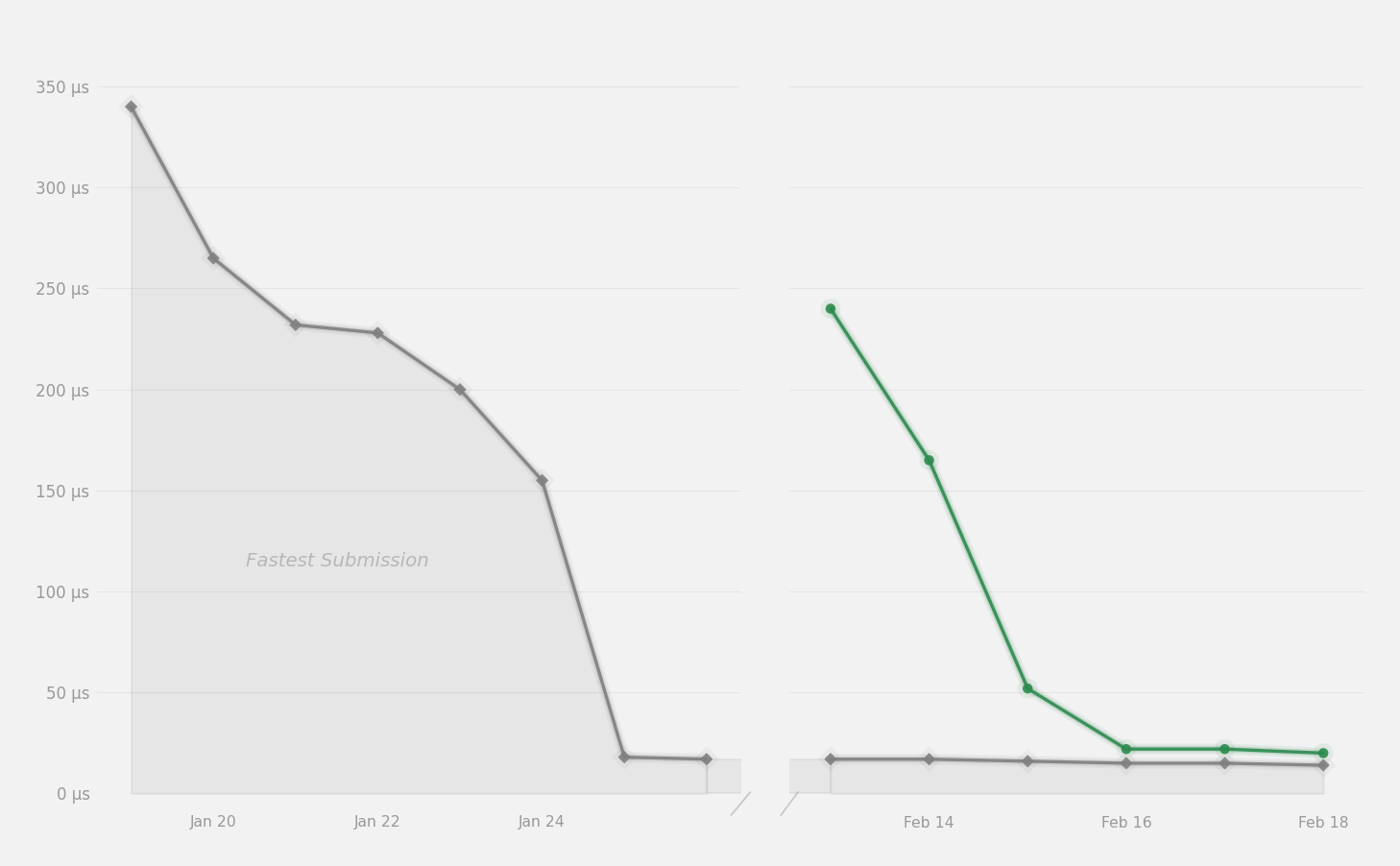
This post discusses my work in optimizing a grouped GEMM kernel for GPUMode's NVFP4 kernel competition.
Recently, GPUMode held a kernel competition for a series of GEMM-like problems using the NVFP4 format, a low precision format introduced with Blackwell B200. The specific kernels are: GEMV, GEMM, Dual GEMM, Grouped GEMM. I competed in both the Dual GEMM and Grouped GEMM leaderboards.
This post will only cover the Grouped GEMM which concluded on Feb 20th, perhaps I'll do a write up of the Dual GEMM in the future.
Foundations of the Kernel
Let’s first outline the workload this kernel targets – Grouped GEMM, and the NVFP4 data format it operates on.
Grouped GEMM and MoE
In Mixture-of-Experts transformers, each token is routed (by a small gating network) to one or more experts, so different experts receive different numbers of tokens every step.
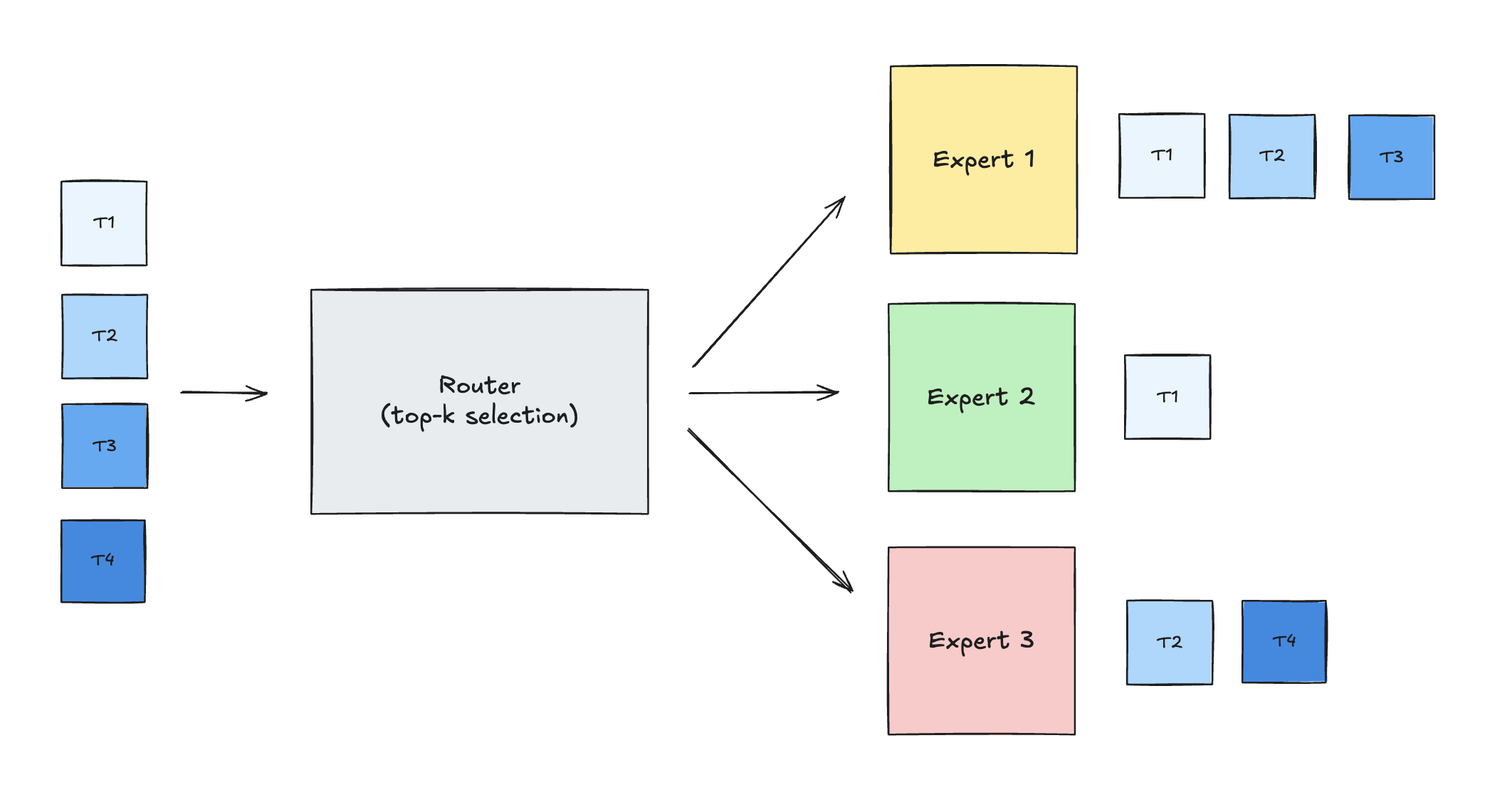
Thus, in terms of a GEMM, the M dimension (corresponding to the number of tokens routed to a specific expert), can vary widely across experts in the same batch. The K and N dimensions are fixed by the model architecture (hidden size and expert count).
When performing a forward pass on an MoE model, there are many independent GEMM problems to solve (one per expert), each with the same K and N but different M. That's where a Grouped GEMM comes handy.
A grouped GEMM is one GPU kernel launch that executes a list of independent GEMMs together. In MoE, this maps directly to routing: each dispatched expert receives a different token subset, so each expert corresponds to one GEMM in that launch list.
Referring to our routing diagram above:
- Expert 1 gets T1, T2, T3 -> GEMM with M=3
- Expert 2 gets T1 -> GEMM with M=1
- Expert 3 gets T2, T4 -> GEMM with M=2
For expert e, the FFN projection is:
1Y_e = X_e @ W_e
where X_e contains activations for tokens routed to expert e, W_e is that expert's weight matrix, and Y_e is that expert's output. So a grouped GEMM is conceptually:
1{ X_1 @ W_1, X_2 @ W_2, X_3 @ W_3, ... }
usually with shared K and N for the layer, but different M_e per expert.
Why this is "grouped": instead of launching one kernel per expert, the host-side passes a problem list in one launch:
1(A_1, B_1, C_1, M_1, N, K) 2(A_2, B_2, C_2, M_2, N, K) 3(A_3, B_3, C_3, M_3, N, K)
Note: the “one expert = one GEMM” portrayal above is a simplification. In a real MoE layer, each expert is usually an FFN/MLP block, not a single matmul. So the real MoE compute is usually structured as multiple grouped GEMM passes across experts, rather than a single grouped GEMM.
At a kernel level, each expert GEMM is split into output tiles, then all tiles from all experts are merged into one global work queue.
SMs then pull tile work dynamically across experts (for example: tile 17 of expert 1, then tile 4 of expert 3, then tile 0 of expert 2).
NVFP4
As large language models push the limits of compute and memory, Blackwell introduced a 4‑bit floating‑point data type, NVFP4, providing developers another lever for improving model efficiency. By packing weights and activations into 4 bits with per‑block scaling, NVFP4 shrinks model size and memory traffic while boosting throughput, all with only modest impact on accuracy.
In terms of representation, the format belongs to the E2M1 4‑bit floating‑point family, with 1 sign bit, 2 exponent bits, and 1 mantissa bit, yielding an effective numeric range of approximately −6 to 6.
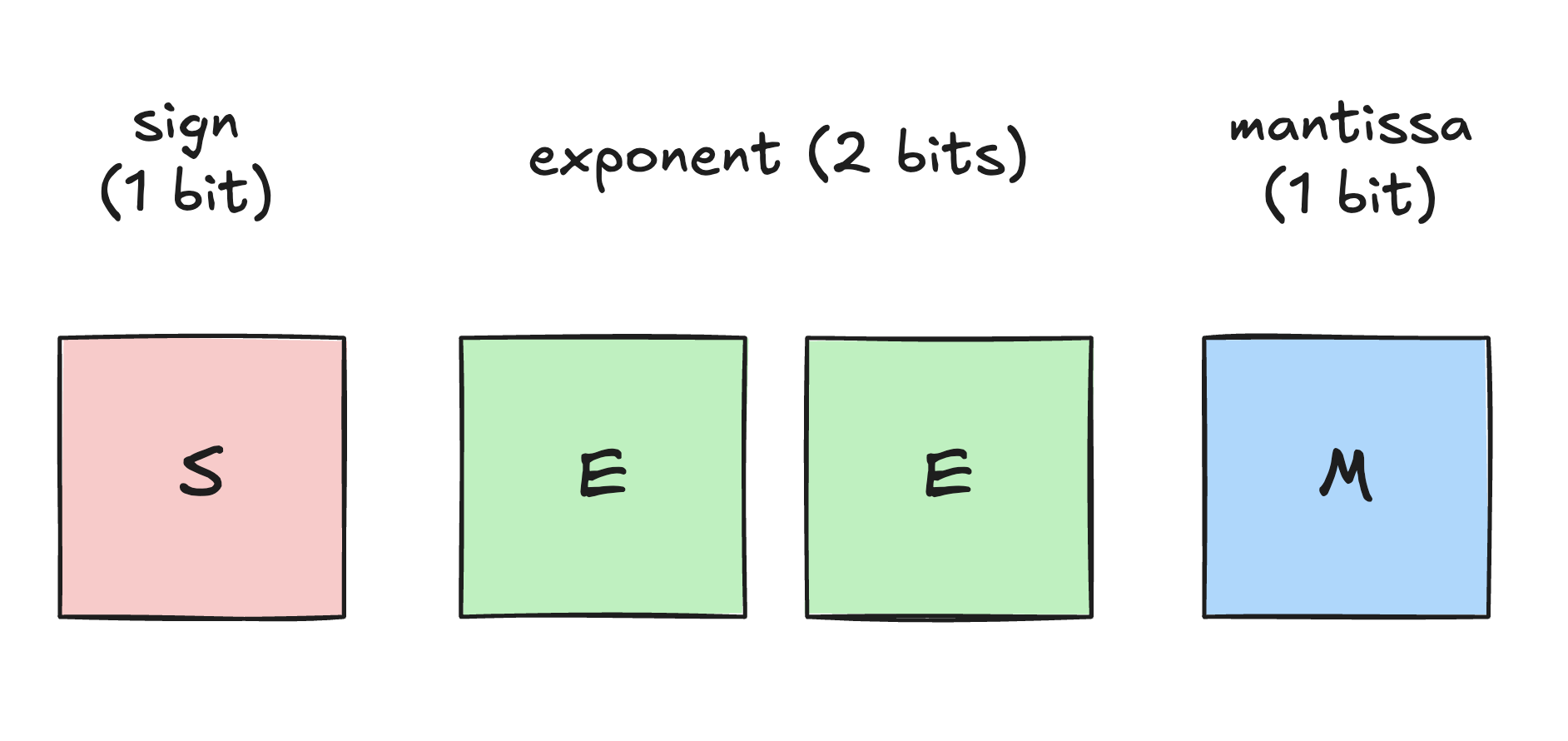
Because of this limited dynamic range, NVFP4 relies on block-level scale factors. For every small block of quantized values (e.g., 16 elements), there is an associated higher-precision scale factor. The true value is recovered by multiplying the 4-bit value by this scale factor.
In the context of our kernel, this means that in addition to loading the primary A and B operand matrices, we must also asynchronously load their corresponding scale factor matrices (SFA and SFB) from global memory into shared memory.
Work in progress...